Sentimental Analysis of popular movies using Managed AWS ML Comprehend service

Abstract
In the ever-growing landscape of data, understanding and extracting valuable information from text data can be a daunting task. AWS Comprehend is a natural language processing (NLP) service provided by Amazon Web Services (AWS) that offers a powerful solution to this challenge.
In this article, we will explore the capabilities and features of AWS Comprehend, and how it can be leveraged to gain insights from text data. All the code snippets are prepared in a single Jupyter notebook that is shared at Links section.
Acknowledgements
AWS Comprehend is a fully managed NLP service that allows developers to analyze text in a variety of ways to extract insights and relationships. It supports multiple languages and provides a suite of tools for tasks such as sentiment analysis, entity recognition, language detection, key phrase extraction, and topic modeling.
Let’s delve into some of the key features and use cases of AWS Comprehend.
AWS Comprehend access
As usual Comprehend provides access to its features from AWS Console:
Also, it is possible to use AWS SDK for programmatic usage, in this post we will use boto3 library.
Detecting PII information
Using comprehend we can detect PII data, chore entities in the text, key phrases, detect languages, sentiments and syntax.
1
2
3
4
5
6
7
8
import boto3
import json
comprehend = boto3.client(service_name='comprehend', region_name='us-east-1')
text = "My name is John and I am 25 years old. My phone number is 000000000000 and my email is XXXXXXXXXXXXXXXX@gmail.com my card is 1111-1111-1111-1111 and pin was 1234"
json_data = comprehend.detect_pii_entities(Text=text, LanguageCode='en')
print(json.dumps(json_data, sort_keys=True, indent=4))
Following response after calling comprehend service we receive what PII categories were detected in the source string and its offsets.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
{
"Entities": [
{
"BeginOffset": 11,
"EndOffset": 15,
"Score": 0.9998698234558105,
"Type": "NAME"
},
{
"BeginOffset": 25,
"EndOffset": 33,
"Score": 0.9999417662620544,
"Type": "AGE"
},
{
"BeginOffset": 58,
"EndOffset": 70,
"Score": 0.9999783039093018,
"Type": "PHONE"
},
{
"BeginOffset": 87,
"EndOffset": 113,
"Score": 0.9991216063499451,
"Type": "EMAIL"
},
{
"BeginOffset": 125,
"EndOffset": 144,
"Score": 0.9999704360961914,
"Type": "CREDIT_DEBIT_NUMBER"
},
{
"BeginOffset": 157,
"EndOffset": 161,
"Score": 0.9999898672103882,
"Type": "PIN"
}
],
"ResponseMetadata": {
"HTTPHeaders": {
"content-length": "484",
"content-type": "application/x-amz-json-1.1",
"date": "Sun, 12 Nov 2023 10:27:44 GMT",
"x-amzn-requestid": "a1d06735-0c52-4ff6-9f83-ae3b9f474383"
},
"HTTPStatusCode": 200,
"RequestId": "a1d06735-0c52-4ff6-9f83-ae3b9f474383",
"RetryAttempts": 0
}
}
The results contain classification of PII data types detected with the probability score abd offset position in the input string.
As we can see the results are pretty accurate - all the PII information was fully identified in our test sentence.
| ID | Score | Type | BeginOffset | EndOffset | ExtractedText |
|---|---|---|---|---|---|
| 0 | 0.999870 | NAME | 11 | 15 | John |
| 1 | 0.999942 | AGE | 25 | 33 | 25 years |
| 2 | 0.999978 | PHONE | 58 | 70 | 000000000000 |
| 3 | 0.999122 | 87 | 113 | XXXXXXXXXXXXXXXX@gmail.com | |
| 4 | 0.999970 | CREDIT_DEBIT_NUMBER | 125 | 144 | 1111-1111-1111-1111 |
| 5 | 0.999990 | PIN | 157 | 161 | 1234 |
Detecting sentiments

1
2
3
4
5
6
7
8
9
martin_luter_talk = """
I say to you today, my friends, so even though we face the difficulties of today and tomorrow,
I still have a dream. It is a dream deeply rooted in the American dream.
I have a dream that one day this nation will rise up and live out the true meaning of its creed:
'We hold these truths to be self-evident, that all men are created equal.
"""
sentiment_output = comprehend.detect_sentiment(Text=martin_luter_talk, LanguageCode='en')
print(json.dumps(sentiment_output, sort_keys=True, indent=4))
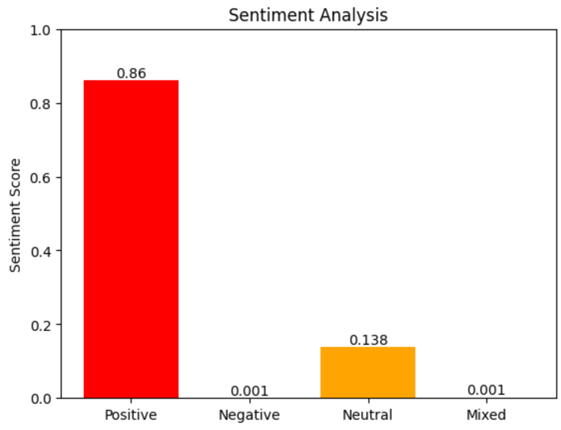
Response contains different types of sentiments with the probability for each of them. Our test speech was marked as positive with probability 86%
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
{
"ResponseMetadata": {
"HTTPHeaders": {
"content-length": "164",
"content-type": "application/x-amz-json-1.1",
"date": "Sun, 12 Nov 2023 10:28:18 GMT",
"x-amzn-requestid": "343f5d13-41b8-41a9-b2d3-74b7bc5542c7"
},
"HTTPStatusCode": 200,
"RequestId": "343f5d13-41b8-41a9-b2d3-74b7bc5542c7",
"RetryAttempts": 0
},
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0.0012894617393612862,
"Negative": 0.0006538676097989082,
"Neutral": 0.1380418837070465,
"Positive": 0.8600147366523743
}
}
Let’s visualise composition of sentiments and probability.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
import matplotlib.pyplot as plt
# SentimentScore data
sentiment_scores = sentiment_output['SentimentScore']
# Plotting
fig, ax = plt.subplots()
colors = ['red', 'blue', 'orange', 'green'] # Define colors for each sentiment
bars = ax.bar(sentiment_scores.keys(), sentiment_scores.values(), color=colors)
# Add labels and title
ax.set_ylabel('Sentiment Score')
ax.set_title('Sentiment Analysis')
ax.set_ylim(0, 1) # Set the y-axis limit to 0-1
# Display the values on top of the bars
for bar in bars:
yval = bar.get_height()
ax.text(bar.get_x() + bar.get_width() / 2, yval, round(yval, 3), ha='center', va='bottom')
# Show the plot
plt.show()
Detect Toxic content Terminator movie

Let’s try to analyse some popular movies for toxic content detection.
First one is from Terminator movie Bar scene, when T200 arrived:
1
2
3
4
5
6
7
8
9
response = comprehend.detect_toxic_content(
TextSegments=[
{
'Text': 'I Need Your Clothes, Your Boots and Your Motorcycle.'
},
],
LanguageCode='en'
)
print(json.dumps(response, sort_keys=True, indent=4))
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
"ResultList": [
{
"Labels": [
{
"Name": "PROFANITY",
"Score": 0.07029999792575836
},
{
"Name": "HATE_SPEECH",
"Score": 0.07109999656677246
},
{
"Name": "INSULT",
"Score": 0.20020000636577606
},
{
"Name": "GRAPHIC",
"Score": 0.01860000006854534
},
{
"Name": "HARASSMENT_OR_ABUSE",
"Score": 0.08330000191926956
},
{
"Name": "SEXUAL",
"Score": 0.15649999678134918
},
{
"Name": "VIOLENCE_OR_THREAT",
"Score": 0.027699999511241913
}
],
"Toxicity": 0.2313999980688095
}
]
aws comprehend could not detect any violence in this sentence, how ever we remember what happened in the Bar after this phrase was said. But it is actually great because T200 was not using any hard expression and had zero emotions :).
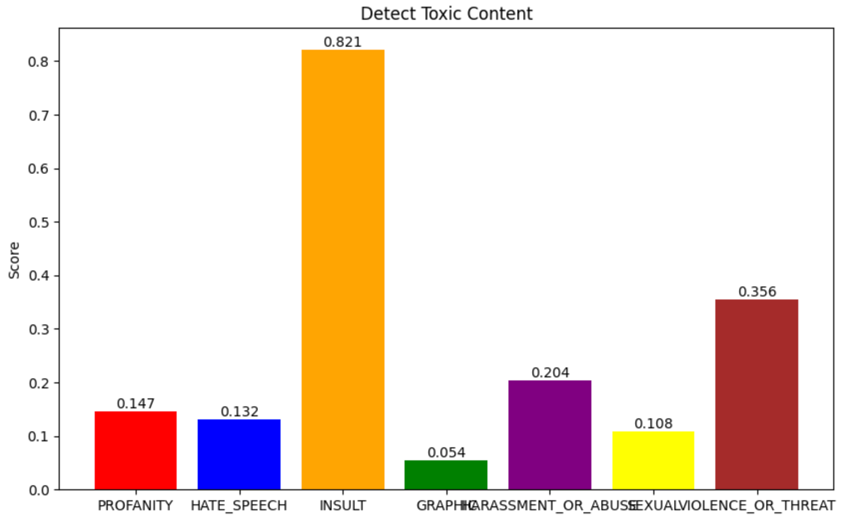
Detect Toxic content God Father movie

1
2
3
4
5
6
7
8
9
response = comprehend.detect_toxic_content(
TextSegments=[
{
'Text': 'Bonasera, Bonasera, what have I ever done to make you treat me so disrespectfully? If you’d come to me in friendship, this scum who ruined your daughter would be suffering this very day. And if by some chance an honest man like yourself made enemies, they would become my enemies. And then, they would fear you.'
},
],
LanguageCode='en'
)
print(json.dumps(response, sort_keys=True, indent=4))
Here results are showing bigger probability of INSULT
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
"ResultList": [
{
"Labels": [
{
"Name": "PROFANITY",
"Score": 0.14669999480247498
},
{
"Name": "HATE_SPEECH",
"Score": 0.1316000074148178
},
{
"Name": "INSULT",
"Score": 0.8208000063896179
},
{
"Name": "GRAPHIC",
"Score": 0.05389999970793724
},
{
"Name": "HARASSMENT_OR_ABUSE",
"Score": 0.20350000262260437
},
{
"Name": "SEXUAL",
"Score": 0.10809999704360962
},
{
"Name": "VIOLENCE_OR_THREAT",
"Score": 0.35569998621940613
}
],
"Toxicity": 0.6919000148773193
}
]
Visual representation