Generation code with AWS CodeWhisperer

Abstract
In recent years, multiple solutions have emerged on the market that aim to increase the productivity of engineers. These solutions provide features such as highlighting, autocompletion, and autosuggestion, which can help developers save time and reduce the likelihood of errors. One of such examples is CodeWhisperer, an AI tool that was announced by AWS in July 2022. CodeWhisperer is similar to GitHub Copilot, which is another tool that provides similar functionality. Both tools use AI algorithms to help developers write code more efficiently by providing suggestions and automating repetitive tasks. For example, CodeWhisperer has been designed to work with a wide range of programming languages, which makes it more versatile than other tools that are focused on a specific language or framework. Additionally, CodeWhisperer is integrated with other AWS services, such as Lambda and S3, which can make it easier for developers to deploy and manage their code.
Based on aws docs: Amazon CodeWhisperer is a general purpose, machine learning-powered code generator that provides you with code recommendations, in real time. As you write code, CodeWhisperer automatically generates suggestions based on your existing code and comments. Your personalized recommendations can vary in size and scope, ranging from a single line comment to fully formed functions.
In this blog post, we will explore CodeWhisperer and see how it performs with simple arithmetic tasks. Additionally, we will also test its ability to interact with an AWS service - CloudWatch - and retrieve metrics for a specific period of time.
CodeWhisperer can also scan your code to highlight and define security issues.
We will use boto3, python. Also, will be interesting to check if it supports additional commands on top of already retrieved results by trying to draw diagram with mathplot for retrieved metric.
The current iteration of CodeWhisperer supports Java, JavaScript, Python, C# and TypeScript. Support for other languages is in development and will be included in future CodeWhisperer releases.
CodeWhisperer in Visual Studio Code IDE
Integration is very simple - it takes just a few steps:
- Install AWS Toolkit extension:
- Create/Reuse our SkillBuilder account:


- We can control Resume/Pause Auto-Suggestions at the left bottom panel of Visual Studio Code:
Asking AWS CodeWhisperer to generate code snippet for math task
First, let’s take a look at how CodeWhisperer handles simple arithmetic tasks. We will use it to find the maximum and average values of a set of numbers, as well as write unit tests for these calculations. CodeWhisperer’s autocompletion and autosuggestion features make it easy to write these tasks quickly and accurately.
Instructions as-a-comments in the code (search minimum in array)
We just start new line with a comment, express human-readable statement for our task. By navigate using Tab and Enter, we can also track CodeWhisperer icon when it performs scan and connects to remote.
# find the smallest number in array
Generated code snippet:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
def find_smallest_number(
# array of ints
arr
):
# initialize smallest to first element in array
smallest = arr[0]
# loop through array and find smallest element
for i in arr:
if i < smallest:
smallest = i
# return smallest
return smallest
Unit test
Let’s ask Whisperer to add unit tests:
# write unit test
Generated code snippet:
1
2
def test_find_smallest_number():
assert find_smallest_number([1, 2, 3, 4, 5]) == 1
Instructions as-a-function signature in the code (calculate average value of elements in array)
Alternative approach is to declare function signature according to a task:
Generated code snippet:
1
2
3
4
5
6
7
8
9
10
11
12
13
def find_avr_number_in_array(
# array of ints
arr
):
# initialize sum
sum = 0
# loop through array and add each element to sum
for i in arr:
sum += i
# return average
return sum / len(arr)
Tests through declared signature
Test through function signature:
Generated tests:
1
2
3
def test_find_avr_number_in_array():
assert find_avr_number_in_array([1, 2, 3, 4, 5]) == 3
assert find_avr_number_in_array([1, 2, 3, 4, 5, 6]) == 3.5
AWS CodeWhisperer query AWS CloudWatch for metrics and generate diagram
Next, we will test CodeWhisperer’s ability to interact with an AWS service - CloudWatch. Specifically, we will use it to retrieve the memory utilization of an ECS service over a certain period of time.
First try
# get maximum, minimum, average memory utilization cloudwatch metric of service named ‘users-service-stg-svc’ running in ecs fargate cluster name ‘staging-fargate-cluster’ for last 2 weeks
Generated code snippet:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
import datetime
import matplotlib.pyplot as plt
import boto3
client = boto3.client('cloudwatch')
response = client.get_metric_statistics(
Namespace='AWS/ECS',
MetricName='MemoryUtilization',
Dimensions=[
{
'Name': 'ClusterName',
'Value': 'staging-fargate-cluster'
},
{
'Name': 'ServiceName',
'Value': 'users-service-stg-svc'
}
],
StartTime='2020-09-01T00:00:00',
EndTime='2020-09-03T00:00:00',
Period=86400,
Statistics=[
'Maximum',
'Minimum',
'Average'
]
)
Output to diagram file
# write response with mathplot
Generated code snippet:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
def plot_response(response):
x = []
y = []
for i in response['Datapoints']:
x.append(i['Timestamp'])
y.append(i['Average'])
plt.plot(x, y)
plt.xlabel('Time')
plt.ylabel('Memory Utilization')
plt.title('Memory Utilization')
plt.show()
First results
We have encountered an issue with generating a visual representation of the metrics retrieved from CloudWatch. While the code executed without error, the resulting diagram was empty, indicating that there were no DataPoints being extracted. Let’s troubleshoot what is wrong.

Wrong Datetime and Period in CloudWatch request
We were querying for a last 2 weeks but code was generated for wrong dates:
1
2
3
StartTime='2020-09-01T00:00:00',
EndTime='2020-09-03T00:00:00',
Period=86400,
In addition to the issue with the empty diagram, we have also discovered that the period for retrieving metrics from CloudWatch is configured with an improper value. This could be causing the lack of DataPoints being extracted and displayed in the diagram.
To resolve this issue, we will adjust the period to an interval of 15 minutes (15 * 60 = 900). By setting the interval to 15 minutes, we will be able to retrieve the necessary metrics in a more accurate and timely manner. This will also provide a more detailed view of the memory utilization of the ECS service over the selected period of time. 15min (15 * 60 = 900) boto3 official doc
Fixed snippet:
1
2
3
StartTime='2023-01-14T00:00:00',
EndTime='2023-01-29T00:00:00',
Period=900,
Graph is not stable
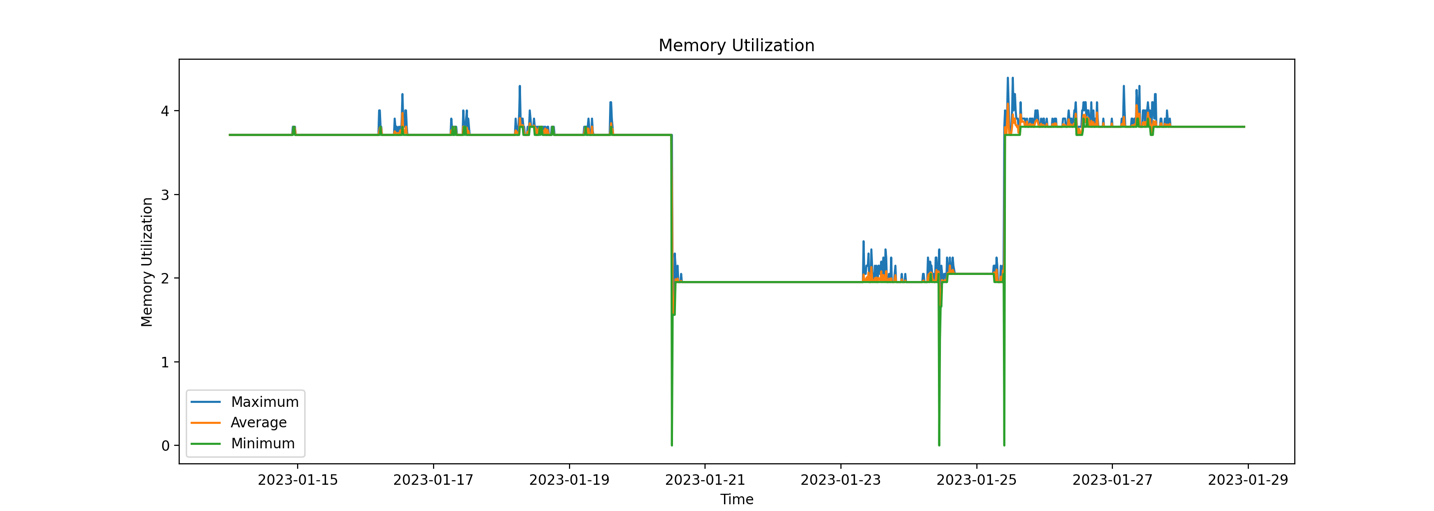
After making the adjustments to the period for retrieving metrics, we were able to generate a visual representation of the memory utilization of the ECS service. However, we have discovered that the data points in the graph are connected in a random order.  The issue is that the DataPoints in the response are in batches, and they should be sorted before rendering based on the datetime. This is a crucial step in ensuring that the data is presented in a logical and understandable manner.
The issue is that the DataPoints in the response are in batches, and they should be sorted before rendering based on the datetime. This is a crucial step in ensuring that the data is presented in a logical and understandable manner.
Let’s add metrics sorting based on datetime
To resolve this issue, we will implement a sorting function to arrange the DataPoints based on the datetime. This will ensure that the data is presented in a chronological order and will make it much easier to interpret the results.
# sort x,y based on x DESC
1
x, y = zip(*sorted(zip(x, y)))
Now diagram has AVR datapoints: 
Not all DataPoints were rendered
But we asked for Maximum, Minimum and Average values. All of them were present in CloudWatch response, but only AVR was rendered. So let’s add all of them to the plot.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
max = []
min = []
avr = []
for i in response['Datapoints']:
x.append(i['Timestamp'])
avr.append(i['Average'])
min.append(i['Minimum'])
max.append(i['Maximum'])
# sort x,y based on x DESC
x, max, avr, min = zip(*sorted(zip(x, max, avr, min)))
plt.plot(x, max)
plt.plot(x, avr)
plt.plot(x, min)
plt.legend(['Maximum', 'Average', 'Minimum'])
By the way, CodeWhisperer proposes to add legend to diagram and also auto suggests plt to add.
Here is our final result:
Let’s also query same CloudWatch Metrics using AWS Console to compare that they are accurate: 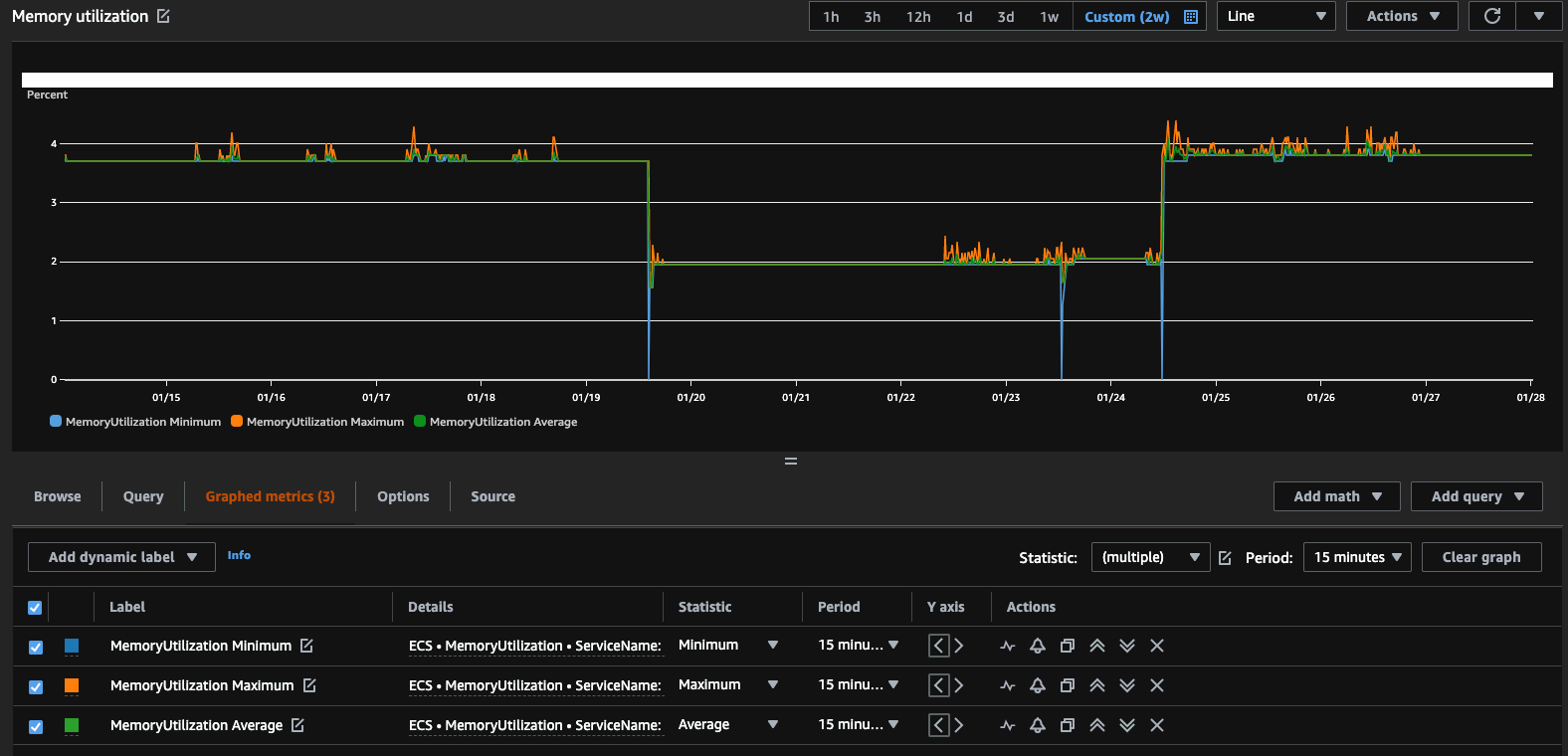
Conclusions
A day before publishing this post CodeWhisperer was generating boto3 client with hardcoded ACCESS and SECRET keys. As we all know that much secure and preferred way is to use aws profiles and roles according to security best practices to assuming execution role. Here is an old snippet: :
1
2
3
4
5
6
client = boto3.client(
'cloudwatch',
aws_access_key_id=aws_access_key_id,
aws_secret_access_key=aws_secret_access_key,
region_name=region_name
)
But, when checking again script generation today from the scratch, I observed that signature had changed to more correct. Now there are no hardcoded values:
1
client = boto3.client('cloudwatch')
Also, for generation of Metric StartTime and EndTime in snippet has changed - now it uses time deltas based on datetime.
1
2
StartTime=datetime.utcnow() - timedelta(days=2),
EndTime=datetime.utcnow(),
Previous code snippet:
1
2
StartTime='2020-09-01T00:00:00',
EndTime='2020-09-03T00:00:00',
This examples in single snippet, shows that ML model is changing in a time and going through its evolution. It will be interesting to compare code generation of same tasks some period of time later to see how CodeWhisperer model will be optimized by that time.
In general, the code after generation was executable. One more extra point is that it was able to combine different tasks (get CloudWatch metric, write to diagram) - the state is transferred - CodeWhisperer was able to parse the response structure and map response fields to proper axis according to the task. But not all of them.
To polish code and make it work still engineer is required. At this moment it is debatable question what is more efficient in terms of time and quality - to check the latest official SDK/lib documentation and write from the scratch or refactor and run through resolving issues in generated snippet.
Right now, we observe the early stage of AI tooling and practices adoption. It will be interesting to see how they will evolve and in what areas they can be applied.