Running inventory on ECS Fargate cluster to optimize resources utilization and reduce your billing costs

Abstract
In this blog post, we will explore how to use Amazon Elastic Container Service (ECS) Fargate to inventory cluster resources, decrease costs and reduce billing. By implementing a few simple strategies, we can save energy and reduce our overall AWS bill.
Cluster vCPU, memory and ephemeral storage retrieval
The first step in reducing costs is to inventory our ECS Fargate cluster resources. This includes identifying the number of tasks, services and inner containers that are running in our cluster. Once we have a clear picture of the resources we are using, we can start to make adjustments to optimize our usage.
Second step is to measure amount of vCPU, memory and storage (both on task and inner container levels) - exactly these three metrics have the biggest impact on the overall billing.
Data collection sequence
flowchart TD
A[Get All Running Tasks] -->|get Task Definition| B[Task CPU/memory, etc.]
B -->|get Innner Containers| C[Container CPU/memory, etc.]
C -->|Transform aggregated| E[Results Metadata]
Aggregated Metadata structure for analysis
classDiagram
class Metadata
Metadata : +string ARN
Metadata : +string region
Metadata : +int cpu
Metadata : +int memory
Metadata : +int container_cpu
Metadata : +int container_memory
Running boto3 python script to collect the data
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
#!/usr/bin/env python3
import boto3
import pickle
client = boto3.client('ecs')
# setup
cluster_name = 'ENTER_YOUR_CLUSTER_NAME'
launchType='FARGATE'
desiredStatus='RUNNING'
response = client.list_tasks(
cluster=cluster_name,
maxResults=100,
desiredStatus=desiredStatus,
launchType=launchType
)
taskDescriptions = client.describe_tasks(
cluster=cluster_name,
tasks=response["taskArns"]
)['tasks']
while "nextToken" in response:
response = client.list_tasks(
cluster=cluster_name,
nextToken=response["nextToken"],
maxResults=100,
desiredStatus=desiredStatus,
launchType=launchType)
taskDescriptions.extend(client.describe_tasks(
cluster=cluster_name,
tasks=response["taskArns"])["tasks"])
metaData = []
for task in taskDescriptions:
total_cpu = 0
total_memory = 0
for container in task["containers"]:
total_cpu = total_cpu + int(container["cpu"])
total_memory = total_memory + int(container["memory"])
cont_cpu = task["containers"][0]["cpu"],
cont_memory= task["containers"][0]["memory"],
taskMetaData = dict(attr = task["attributes"][0]["value"],
az = task["availabilityZone"],
# Sum total of containers
total_containers = len(task["containers"]),
total_container_memory = total_memory,
total_container_cpu = total_cpu,
cpu = task["cpu"],
memory = task["memory"],
platform = task["platformFamily"],
platform_ver = task["platformVersion"],
ephemeralStorage = task["ephemeralStorage"]["sizeInGiB"],
taskDefinitionArn = task["taskDefinitionArn"])
metaData.append(taskMetaData)
with open(cluster_name + ".data", "wb") as outfile:
pickle.dump(metaData, outfile)
print("Cluster Dump saved")
Cluster configuration analysis using extracted data
Now having the data extracted and available, we can use any analysis library to perform aggregation, visualize and calculate. Here I’m using Pandas
When using Amazon Elastic Container Service (ECS) Fargate, it is important to ensure that the task is properly mapped to the resources of the inner container.
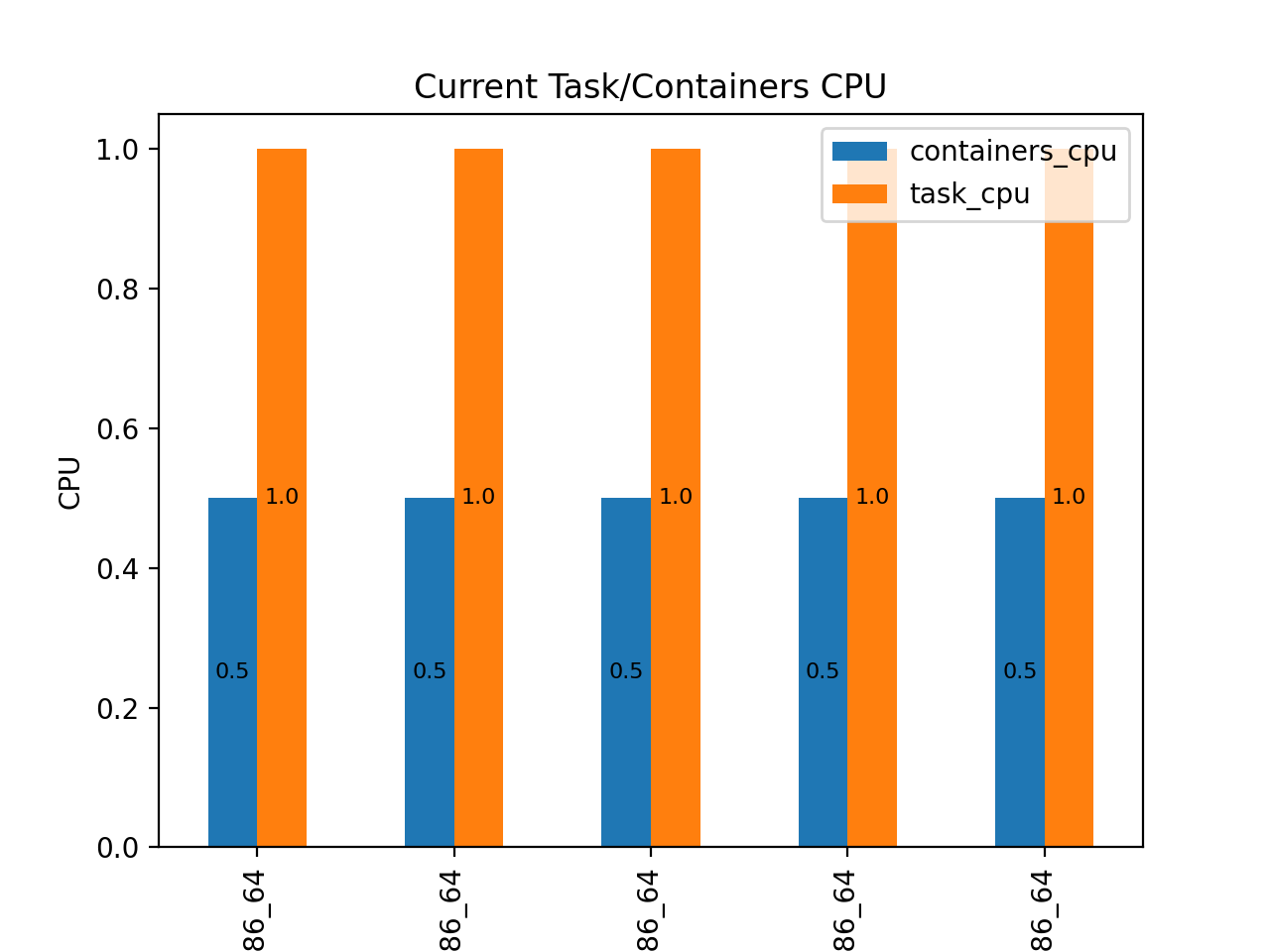 A common problem that can occur is when a Fargate task is mapped with more vCPU and memory resources than the inner container actually needs.
A common problem that can occur is when a Fargate task is mapped with more vCPU and memory resources than the inner container actually needs.
When a Fargate task is over-allocated with vCPU and memory resources, it can lead to a number of issues.
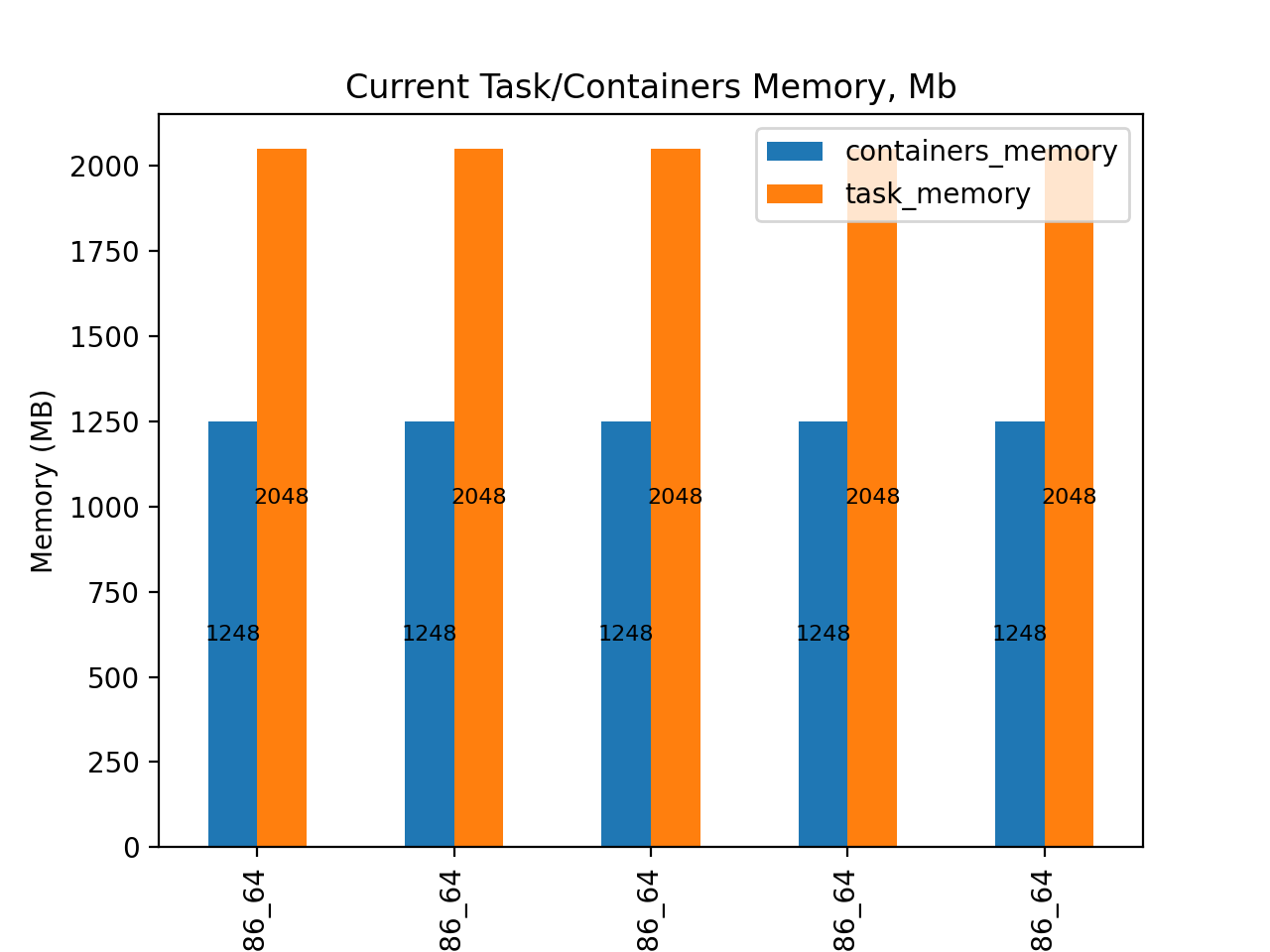 One issue is that the task may not be able to fully utilize the resources that have been allocated to it, resulting in wasted resources and increased costs. Additionally, the task may experience performance issues, such as slow response times, due to the over allocation of resources.
One issue is that the task may not be able to fully utilize the resources that have been allocated to it, resulting in wasted resources and increased costs. Additionally, the task may experience performance issues, such as slow response times, due to the over allocation of resources.
Another issue that can occur is that the task may consume more resources than the container is configured to handle, resulting in the container crashing or becoming unresponsive. This can cause downtime for our application and lead to a poor user experience.
From current distribution we observe that vCPU size allocation for ECS task is 2 times more than configured for inner running docker container. The same situation is for memory ~40%.
Analysed configuration not only limits the container’s ability to utilize additional resources that are available at the task level, but also results in overpayment for resource usage. Furthermore, the container may experience Out Of Memory (OOM) errors and terminate, unable to utilize the memory allocated at the task level. The diagrams below illustrates the CPU and memory distribution for five tasks within the ECS cluster.
Running analysis
Head 5 records from the cluster:
1
2
3
4
5
6
7
8
9
10
Loaded ECS dump
Analyse cluster: YOUR-cluster.data
attr az total_containers total_container_memory total_container_cpu ... memory platform platform_ver ephemeralStorage taskDefinitionArn
0 x86_64 us-west-1b 1 1248 512 ... 2048 Linux 1.4.0 20 arn:aws:ecs:us-west-1:ACCOUNT_ID:task-defini...
1 x86_64 us-west-1a 1 1248 512 ... 2048 Linux 1.4.0 20 arn:aws:ecs:us-west-1:ACCOUNT_ID:task-defini...
2 x86_64 us-west-1a 1 1248 512 ... 2048 Linux 1.4.0 20 arn:aws:ecs:us-west-1:ACCOUNT_ID:task-defini...
3 x86_64 us-west-1b 1 1248 512 ... 2048 Linux 1.4.0 20 arn:aws:ecs:us-west-1:ACCOUNT_ID:task-defini...
4 x86_64 us-west-1b 1 1248 512 ... 2048 Linux 1.4.0 20 arn:aws:ecs:us-west-1:ACCOUNT_ID:task-defini...
...
[5 rows x 11 columns]
pie
title Tasks distribution based on cpu/memory
"1vCPU/2048Mb" : 236
"4vCPU/8192" : 13
"0.5vCPU/1024" : 1
Calculate AWS billing for current cluster:
AWS uses following billing formula applied to ECS loads (more info aws fargate pricing)
1
2
3
Total vCPU charges = (# of Tasks) x (# vCPUs) x (price per CPU-second) x (CPU duration per day by second) x (# of days)
Total memory charges = (# of Tasks) x (memory in GB) x (price per GB) x (memory duration per day by second) x (# of days)
Total ephemeral storage charges = (# of Tasks) x (additional ephemeral storage in GB) x (price per GB) x (memory duration per day by second) x (# of days)
Applied AWS billing formula for current cluster:
1
2
3
4
5
6
7
8
9
10
Current billing
attr az total_containers total_container_memory total_container_cpu ... memory_price_month storage_price_day storage_price_month total_day total_month
0 x86_64 us-west-1b 1 1248 512 ... 6.61416 0.0 0.0 1.18488 36.73128
1 x86_64 us-west-1a 1 1248 512 ... 6.61416 0.0 0.0 1.18488 36.73128
2 x86_64 us-west-1a 1 1248 512 ... 6.61416 0.0 0.0 1.18488 36.73128
3 x86_64 us-west-1b 1 1248 512 ... 6.61416 0.0 0.0 1.18488 36.73128
4 x86_64 us-west-1b 1 1248 512 ... 6.61416 0.0 0.0 1.18488 36.73128
.. ... ... ... ... ... ... ... ... ... ... ...
[XXX rows x 19 columns]
Applied AWS billing formula to calculate overpay:
1
2
3
4
5
6
7
8
9
Overpay
attr az total_containers total_container_memory ... cpu_used_percent cpu_unused_percent memory_unused_percent total_month_overpay
0 x86_64 us-west-1b 1 1248 ... 50.0 50.0 39.0625 17.642216
1 x86_64 us-west-1a 1 1248 ... 50.0 50.0 39.0625 17.642216
2 x86_64 us-west-1a 1 1248 ... 50.0 50.0 39.0625 17.642216
3 x86_64 us-west-1b 1 1248 ... 50.0 50.0 39.0625 17.642216
4 x86_64 us-west-1b 1 1248 ... 50.0 50.0 39.0625 17.642216
.. ... ... ... ... ... ... ... ... ...
[XXX rows x 26 columns]
Good news are that we are not use ephemeral storage more than minimal allocation of ECS Task, so no extra bills here. But there is a room for improvement of vCPU and memory allocation.
Current cluster resources billing base ECS Task size (real values are obfuscated)
1
2
3
4
5
6
7
Current monthly billing SUM
sum count
cpu memory total_container_memory total_container_cpu
1024 2048 1248 512 XXXX.XX XXX
1504 640 XXXX.XX XXX
4096 8192 8192 4096 XXXX.XX XXX
512 1024 768 384 XXXX.XX XXX
Current cluster resources overpay base ECS Task size (real values are obfuscated)
1
2
3
4
5
6
7
Overpay SUM
sum count
cpu memory total_container_memory total_container_cpu
1024 2048 1248 512 YYYY.YY XXX
1504 640 YYYY.YY XXX
4096 8192 8192 4096 0 XXX
512 1024 768 384 Y XXX
Mean unused cpu/memory grouped by task type:
| cpu | memory | container_memory | container_cpu | memory_unused_% | cpu_unused_% |
|---|---|---|---|---|---|
| 1024 | 2048 | 1248 | 512 | 39.0625 | 50.0 |
| 1504 | 2048 | 1248 | 640 | 26.5625 | 37.5 |
| 4096 | 8192 | 8192 | 4096 | 0.0000 | 0.0 |
| 512 | 1024 | 768 | 384 | 25.0000 | 25.0 |
Available AWS options for ECS tasks resources allocation
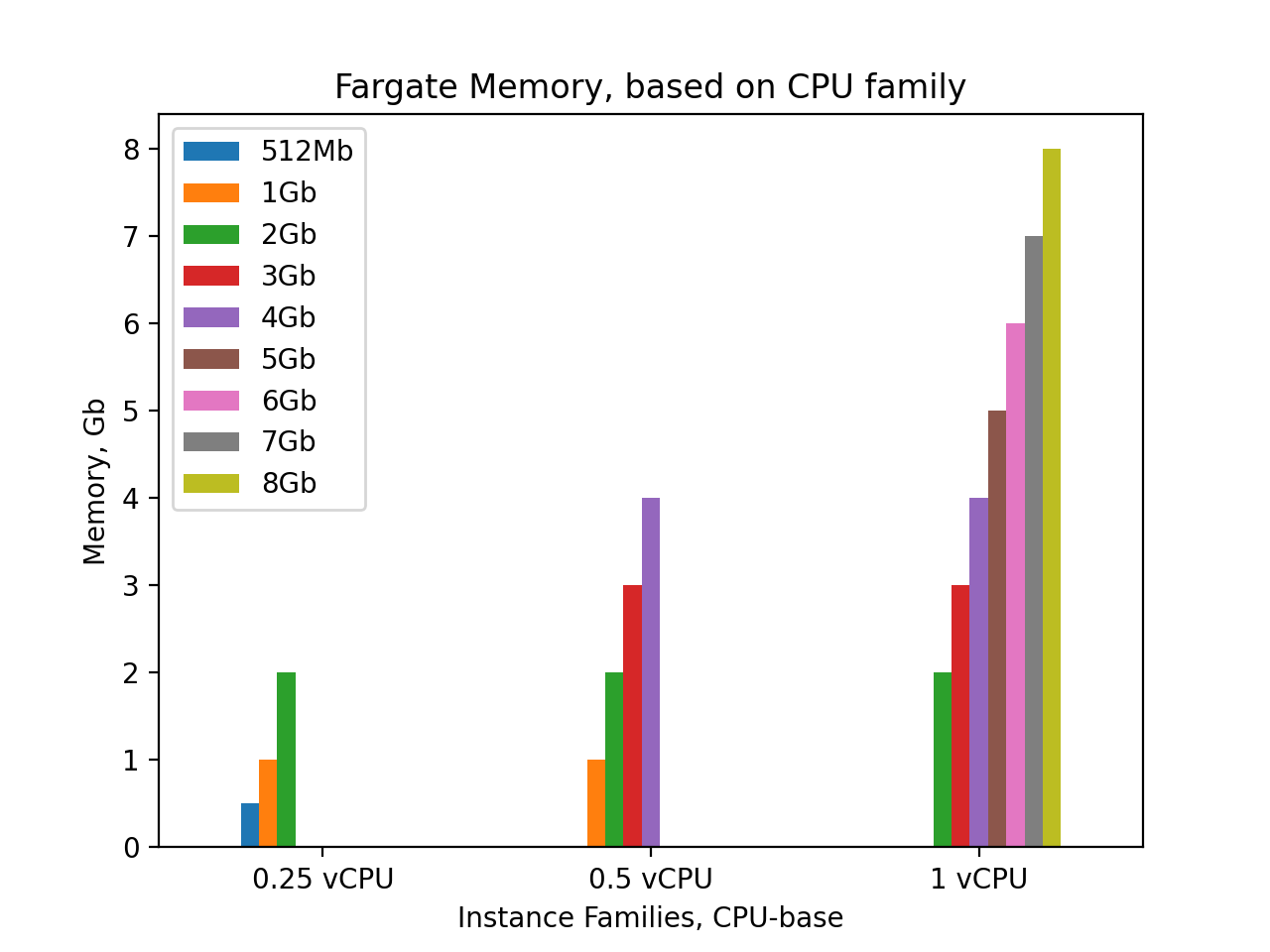 Now it’s time to choose the proper size ECS task that will fit our required container vCPU and memory size.
Now it’s time to choose the proper size ECS task that will fit our required container vCPU and memory size.
On this diagram I have grouped different existing AWS task options in terms of memory based on amount of CPU. For 1vCPU we have 7 memory options: [2, 3, 4, 5 ,6, 7, 8] Gb, for 0.5CPU only 4 options: [1, 2, 3, 4] Gb. For full variety of other CPU options we can reference AWS documentation: AWS provides different options resources allocation for tasks depending on amount of vCPU attached aws official
In our current scenario, the most viable option is to migrate XXX Tasks from 1vCPU/2048Gb to 0.5vCPU/2048Gb. Due to Docker container is configured to use 1248Mb, reducing the vCPU to 0.5 while keeping the memory at 2048Gb is a more efficient utilization of resources. However, if an analysis of the memory consumption of our application reveals that it can fit within 1024Gb with a buffer, then the next best option would be to use 0.5vCPU/1024Gb ECS task definitions. This will not only decrease the billing by half but also ensure that all allocated resources are utilized efficiently.
Further tuning
After ensuring that all containers and tasks are correctly sized and there are no blind spots, proceed to the next step of optimization. Utilize knowledge of our workloads’ details, including expected system requirements and behavior under load, to conduct benchmarks and measure actual resource consumption.
By comparing these metrics, determine if there is room for further improvement. If so try downscaled task resources on pre-prod environment, verify its behavior and after that move changes to prod.
Conclusions
Periodically conducting inventory on our setups is crucial to maintain consistency, as various factors such as configuration drift, rush releases, and manual interactions can cause deviations. Additionally, incorporating a feature in the AWS console that displays the utilization percentage of resources or the carbon impact of an ECS cluster would provide valuable insights.