Running Recommendation Engine Spark Job on EMR

Abstract
Amazon Elastic MapReduce (EMR) is a managed big data service that simplifies the process of processing and analyzing large datasets using popular frameworks like Apache Spark, Hadoop, and others. In this post, we’ll focus on using EMR with Apache Spark to read data from Amazon S3, a scalable object storage service offered by AWS.
Target Infrastructure

EMR Setup
Frameworks and versions configuration
Setting up an EMR cluster from the AWS Console is a easy thanks to the intuitive wizard steps. The latest available EMR version, emr-6.13.0, ensures you have access to the most up-to-date features and improvements.
During the configuration process, you have the flexibility to choose from a variety of frameworks. These frameworks are automatically provisioned and ready to use on your EMR cluster. Should you require a specific version, you can easily adjust it to meet your needs.
One of the standout features of EMR is the provision of preconfigured installations. AWS offers a selection of installations with different engines and compatible versions that have undergone rigorous testing and alignment. This is a game-changer in the Big Data landscape, as it eliminates the challenges and BIG pain in Big Data World of assembling a distribution with all frameworks precisely aligned to dedicated versions and simplifies the upgrade process. With EMR, everything is prepped and ready for seamless use.

Primary node capacity
The primary node serves as the central management hub for the cluster. It oversees critical components of distributed applications, including the YARN ResourceManager service for resource management. Additionally, the primary node is responsible for running the HDFS NameNode service, keeping track of job statuses, and monitoring the overall health of the instance groups.
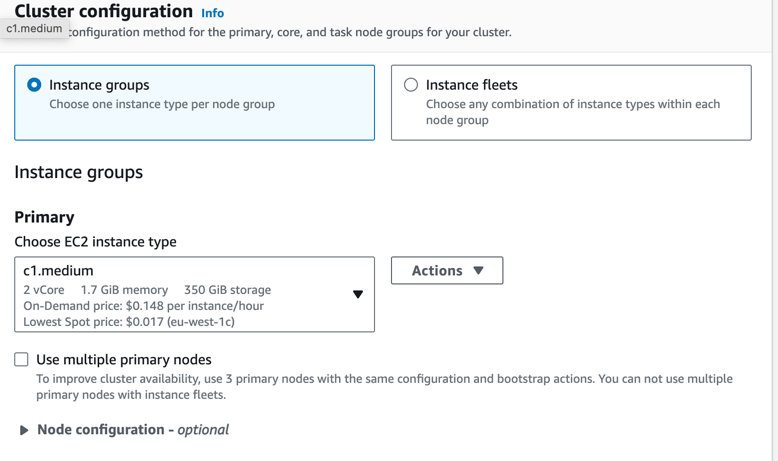
Core node capacity
Under the primary node’s management, core nodes play a pivotal role in data coordination within the Hadoop Distributed File System (HDFS). They execute the Data Node daemon, which handles data storage tasks. Core nodes are also responsible for running the Task Tracker daemon, performing parallel computations required by installed applications. For instance, a core node hosts YARN NodeManager daemons, executes Hadoop MapReduce tasks, and handles Spark executors.
Task node capacity
Task nodes are your go-to choice when you need additional processing power. They excel at executing tasks like Hadoop MapReduce tasks and Spark executors. Unlike core nodes, task nodes do not run the Data Node daemon, nor do they store data in HDFS. To incorporate task nodes into your cluster, you can either add Amazon EC2 instances to an existing uniform instance group or adjust target capacities for a task instance fleet. This flexibility allows you to fine-tune your cluster’s computational capabilities to meet specific workload requirements.

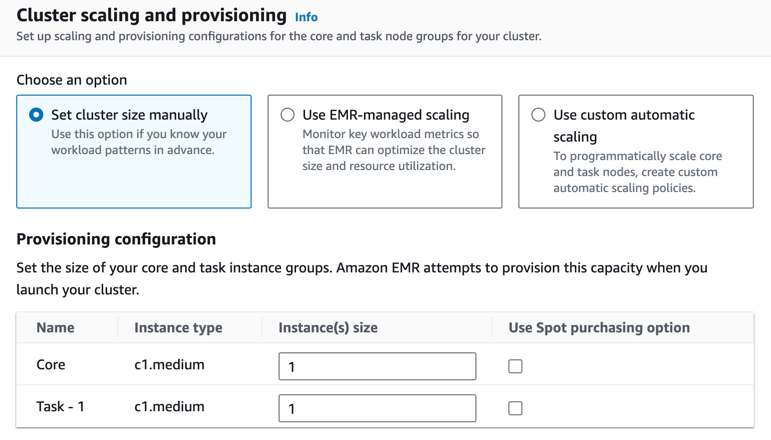
Cluster size
Based on workload time you can configure and tune cluster capacity with autoscaling options.
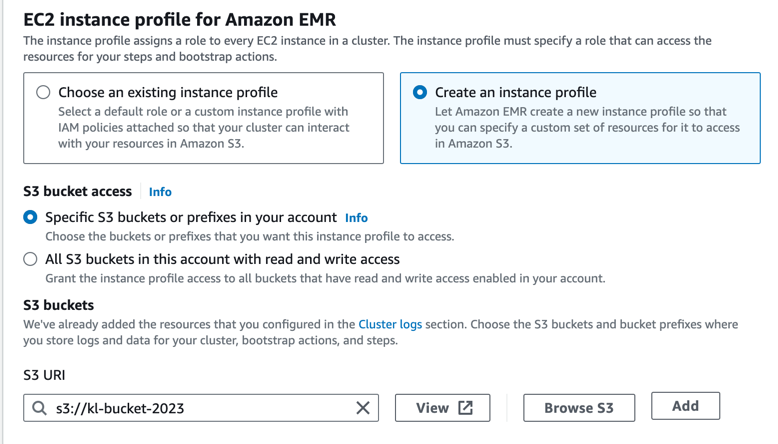
Acces to S3 with Data
Enable access to Nodes from your machine
By default, when EMR is created there is no access to nodes for end-user. We need to edit Security Group of the Primary Node and add appropriate rule to access EC2 instance.
After configuring SG we can ssh into Primary node of EMR:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
ssh -i ~/ssh.pem hadoop@ec2-xx-xxx-xxx-xx.eu-west-1.compute.amazonaws.com
, #_
~\_ ####_ Amazon Linux 2
~~ \_#####\
~~ \###| AL2 End of Life is 2025-06-30.
~~ \#/ ___
~~ V~' '->
~~~ / A newer version of Amazon Linux is available!
~~._. _/
_/ _/ Amazon Linux 2023, GA and supported until 2028-03-15.
_/m/' https://aws.amazon.com/linux/amazon-linux-2023/
5 package(s) needed for security, out of 11 available
Run "sudo yum update" to apply all updates.
EEEEEEEEEEEEEEEEEEEE MMMMMMMM MMMMMMMM RRRRRRRRRRRRRRR
E::::::::::::::::::E M:::::::M M:::::::M R::::::::::::::R
EE:::::EEEEEEEEE:::E M::::::::M M::::::::M R:::::RRRRRR:::::R
E::::E EEEEE M:::::::::M M:::::::::M RR::::R R::::R
E::::E M::::::M:::M M:::M::::::M R:::R R::::R
E:::::EEEEEEEEEE M:::::M M:::M M:::M M:::::M R:::RRRRRR:::::R
E::::::::::::::E M:::::M M:::M:::M M:::::M R:::::::::::RR
E:::::EEEEEEEEEE M:::::M M:::::M M:::::M R:::RRRRRR::::R
E::::E M:::::M M:::M M:::::M R:::R R::::R
E::::E EEEEE M:::::M MMM M:::::M R:::R R::::R
EE:::::EEEEEEEE::::E M:::::M M:::::M R:::R R::::R
E::::::::::::::::::E M:::::M M:::::M RR::::R R::::R
EEEEEEEEEEEEEEEEEEEE MMMMMMM MMMMMMM RRRRRRR RRRRRR
[hadoop@ip-xxx-xx-xx-xx ~]$
Access to YARN, Spark History:
You can use ssh tunnel to expose EMR ports with YARN, Spark to you local machine and access them. But in the latest EMR UI version AWS Console provides link to navigate directly to provisioned proxy instances.
1
ssh -i ~/key.cer -L 3000:ec2-xx-xxx-xxx-xx.eu-west-1.compute.amazonaws.com:8088 hadoop@ec2-xx-xxx-xxx-xx.eu-west-1.compute.amazonaws.com
1
2
3
4
ssh -i ~/key.cer -L 4040:SPARK_UI_NODE_URL:4040 hadoop@ec2-xx-xx-xx-xx.eu-west-1.compute.amazonaws.com
ssh -i ~/key.cer -N -L 20888:ip-xx-xx-xx-xx.your-region.compute.internal:20888 hadoop@ec2-xxx.compute.amazonaws.com
ssh -i ~/key.cer -L 3000:ec2-xx-xx-xx-xx.eu-west-1.compute.amazonaws.com:8088 hadoop@ec2-xx-xx-xx-xx.eu-west-1.compute.amazonaws.com
ssh -i ~/key.cer -L 4040:ec2-xx-xx-xx-xx.eu-west-1.compute.amazonaws.com:4040 hadoop@ec2-xxx-xx-xx-xx.eu-west-1.compute.amazonaws.com
Running Sample Spark Job
To test EMR Spark functionality we will start with predefided Spark sample app, let’s dive into its details.
1
cp /usr/lib/spark/examples/src/main/python/ml/als_example.py ./
Spark Load Data from HDFS, splited based on :: delimiter to userID, movieID, rating, timestamp:
1
2
3
4
5
lines = spark.read.text("data/mllib/als/sample_movielens_ratings.txt").rdd
parts = lines.map(lambda row: row.value.split("::"))
ratingsRDD = parts.map(lambda p: Row(userId=int(p[0]), movieId=int(p[1]),
rating=float(p[2]), timestamp=int(p[3])))
ratings = spark.createDataFrame(ratingsRDD)
Spark Train Model for recommendations using ALS on training Data:
1
2
3
als = ALS(maxIter=5, regParam=0.01, userCol="userId", itemCol="movieId", ratingCol="rating",
coldStartStrategy="drop")
model = als.fit(training)
Predictions, Model Evaluation:
- generate top 10 movie recommendations for each user
- generate top 10 user recommendations for each movie
1
2
3
4
5
6
7
8
predictions = model.transform(test)
evaluator = RegressionEvaluator(metricName="rmse", labelCol="rating",
predictionCol="prediction")
rmse = evaluator.evaluate(predictions)
print("Root-mean-square error = " + str(rmse))
userRecs = model.recommendForAllUsers(10)
movieRecs = model.recommendForAllItems(10)
- generate top 10 movie recommendations for a specified set of users
- generate top 10 user recommendations for a specified set of movies
1
2
3
4
5
6
users = ratings.select(als.getUserCol()).distinct().limit(3)
userSubsetRecs = model.recommendForUserSubset(users, 10)
movies = ratings.select(als.getItemCol()).distinct().limit(3)
movieSubSetRecs = model.recommendForItemSubset(movies, 10)
Load data to HDFS
DataSet is available at https://github.com/tsypuk/samples/tree/main/emr to copy it to HDFS we are using hadoop cli
1
2
hadoop fs -mkdir -p /user/hadoop/data/mllib/als
hadoop fs -copyFromLocal /usr/lib/spark/data/mllib/als/sample_movielens_ratings.txt /user/hadoop/data/mllib/als/sample_movielens_ratings.txt
Optional Stage
Modify spark Job to have less output in logs
1
spark.sparkContext.setLogLeve("ERROR")
Submitting Spark Job
1
2
3
4
5
6
7
[hadoop@ip-xxx-xx-xx-xx ~]$ spark-submit als_example.py
23/10/18 14:03:34 INFO SparkContext: Running Spark version 3.4.1-amzn-0
23/10/18 14:03:34 INFO ResourceUtils: ==============================================================
23/10/18 14:03:34 INFO ResourceUtils: No custom resources configured for spark.driver.
23/10/18 14:03:34 INFO ResourceUtils: ==============================================================
23/10/18 14:03:34 INFO SparkContext: Submitted application: ALSExample
23/10/18 14:03:34 INFO ResourceProfile: Default ResourceProfile created, executor resources: Map(cores -> name: cores, amount: 4, script: , vendor: , memory -> name: memory, amount: 9486, script: , vendor: , offHeap -> name: offHeap, amount: 0, script: , vendor: ), task resources: Map(cpus -> name: cpus, amount: 1.0)
Results and Status are available on UI

Output of results in console:
Here are recommendations for each user for current DataSet:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
+------+--------------------+
|userId| recommendations|
+------+--------------------+
| 4|[{41, 4.165862}, ...|
| 14|[{76, 4.606556}, ...|
| 24|[{69, 5.097545}, ...|
| 5|[{55, 4.787237}, ...|
| 15|[{46, 4.87731}, {...|
| 25|[{38, 4.6747584},...|
| 6|[{62, 4.7941403},...|
| 16|[{85, 5.0937176},...|
| 26|[{74, 5.545739}, ...|
| 27|[{18, 4.022548}, ...|
| 17|[{27, 5.4436226},...|
| 7|[{25, 4.7733192},...|
| 20|[{22, 4.6535172},...|
| 0|[{92, 3.967172}, ...|
| 10|[{2, 3.6862848}, ...|
| 1|[{68, 3.9590843},...|
| 11|[{27, 4.9718685},...|
| 21|[{53, 4.8786216},...|
| 12|[{46, 6.7249556},...|
| 2|[{83, 5.306094}, ...|
+------+--------------------+
only showing top 20 rows
Switching EMR Spark to query AWS S3
It was sampled Spark job that works with HDFS, but for EMR AWS S3 is available
DataSet located S3 bucket (with prefixed virtual path based on timeline) we will use from the previous post Connecting Kinesis Firehose DataStream with aws-kinesis-agent to ingest Log Data into AWS S3
To make EMR Spark work with S3 we need to modify the Job file:
1
2
3
4
5
6
7
8
lines = spark.read.text("s3://kl-bucket-2023/year=2023/month=10/day=18/hour=13/*").rdd
parts = lines.map(lambda row: row.value.split(','))
#Filter out postage, shipping, bank charges, discounts, commissions
productsOnly = parts.filter(lambda p: p[1][0:5].isdigit())
#Filter out empty customer ID's
cleanData = productsOnly.filter(lambda p: p[6].isdigit())
ratingsRDD = cleanData.map(lambda p: Row(customerId=int(p[6]), \
itemId=int(p[1][0:5]), rating=1.0))
Troubleshooting the issue
I case you receive you receiving following error when running Job:
1
Caused by: com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.services.s3.model.AmazonS3Exception: Access Denied (Service: Amazon S3; Status Code: 403; Error Code: AccessDenied;
Try to check if EMR has access to S3 by running the following cli command:
1
2
hdfs dfs -ls s3://kl-bucket-2023/year=2023/month=10/day=18/hour=13/*
ls: com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.services.s3.model.AmazonS3Exception: Access Denied
If error - check Service Role and EC2 instance profile - they should have access to your s3 bucket. Once permissions are setup, you should see the proper bucket listing:
1
2
3
4
[hadoop@ip-xx-xx-xx-xx ~]$ hdfs dfs -ls s3://kl-bucket-2023hdfs dfs -ls s3://kl-bucket-2023/year=2023/month=10/day=18/hour=13/*
-rw-rw-rw- 1 hadoop hadoop 423974 2023-10-18 13:02 s3://kl-bucket-2023/year=2023/month=10/day=18/hour=13/terraform-kinesis-firehose-logs-s3-stream-1-2023-10-18-13-01-08-e7f44bf7-b2e0-43b7-ad1c-11d74c7383fa
-rw-rw-rw- 1 hadoop hadoop 837497 2023-10-18 13:13 s3://kl-bucket-2023/year=2023/month=10/day=18/hour=13/terraform-kinesis-firehose-logs-s3-stream-1-2023-10-18-13-12-31-efad7e9e-89a1-4478-9a09-b954dd83c48d
-rw-rw-rw- 1 hadoop hadoop 1257779 2023-10-18 13:14 s3://kl-bucket-2023/year=2023/month=10/day=18/hour=13/terraform-kinesis-firehose-logs-s3-stream-1-2023-10-18-13-13-43-35e7b0b8-90a4-449a-b373-82f14e28032f
Running Spark Job on top of S3 Data
After submitting Spark Job, now it works and queries Data from partitions prefixes S3 Bucket:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
+----------+--------------------+
|customerId| recommendations|
+----------+--------------------+
| 15992|[{22983, 1.283649...|
| 15237|[{21064, 1.094786...|
| 17668|[{85114, 1.253556...|
+----------+--------------------+
+------+--------------------+
|itemId| recommendations|
+------+--------------------+
| 21209|[{17119, 1.570859...|
| 22129|[{16402, 0.956514...|
| 22429|[{16781, 1.282029...|
+------+--------------------+
Acknowledgements
EMR makes it easy to provision resources, scale instances submit and monitor jobs. Regarding storage besides standard HDFS it provides EMRFS - a robust implementation of Hadoop Distributed File System (HDFS) used by all Amazon EMR clusters. It empowers clusters to seamlessly read and write regular files from Amazon EMR directly to Amazon S3, offering a blend of convenience and powerful features.