Challenges with Transferring DynamoDB Table using native AWS DynamoDB Import/Export from S3. Implementing own importing tool.

Abstract
Transferring DynamoDB tables using AWS DynamoDB Import/Export from Amazon S3 can be a powerful solution for data migration. However, there are certain challenges that may arise during the process. This article aims to explore common problems encountered during DynamoDB transfers and propose an efficient import tool to address these issues.
How AWS Native Import/Export works
Using DynamoDB table export, you can export data from an Amazon DynamoDB table from any time within your point-in-time recovery window to an Amazon S3 bucket. Exporting a DynamoDB table to an S3 bucket enables you to perform analytics and complex queries on your data using other AWS services such as Athena, AWS Glue, and Lake Formation. DynamoDB table export is a fully managed solution for exporting DynamoDB tables at scale, and is much faster than other workarounds involving table scans.
Import
The import process is straightforward and user-friendly. You can effortlessly select the source table you want to import and then specify the destination S3 bucket where the import files will be stored.
By following a few simple steps, you can initiate the import process without any complications. First, identify the source table that holds the data you wish to import. Then, select the appropriate S3 bucket where the data will be stored during the import process.
Please note that PITR (Point-in-time recovery) should be enabled first on Table level to perform export
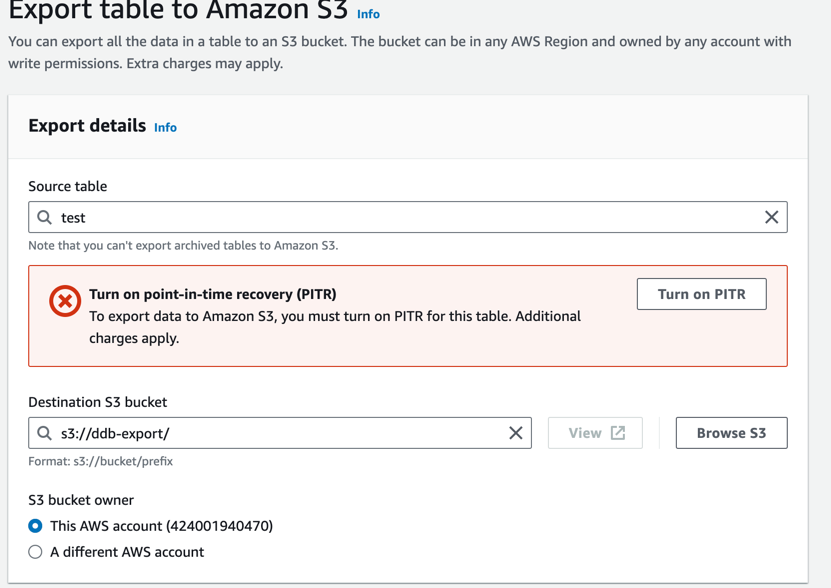
During the import process, an import job is created, and you can conveniently track its progress through the AWS console. However, it’s important to note that even for smaller tables, the import operation may still take a short while, approximately around 5 minutes. This duration is primarily due to the necessary provisioning of the infrastructure framework required to execute the import.
Export
During the Export process, a user-friendly wizard guides you through each step, making it simple to set up the export according to your preferences. First, you specify the source S3 bucket containing the data dump you wish to export. Next, you select the desired format for the export, ensuring compatibility with your target system.
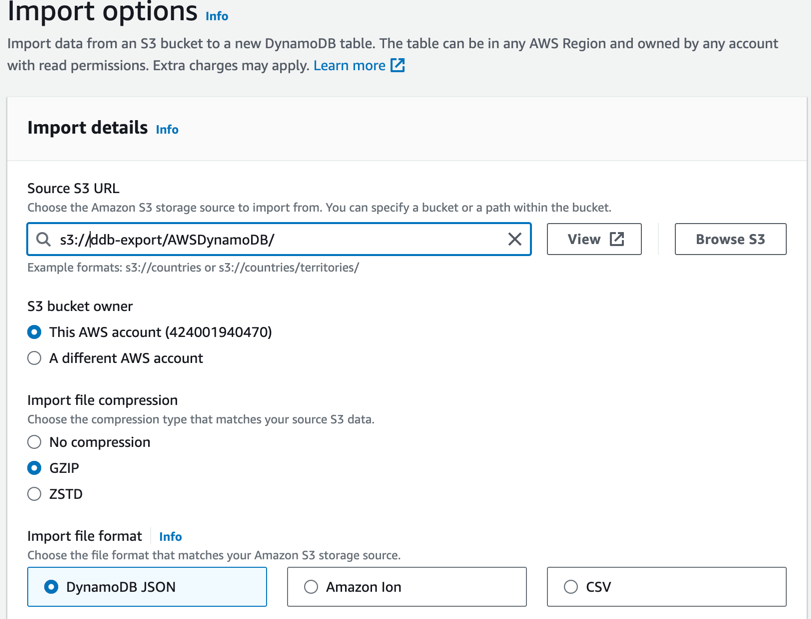
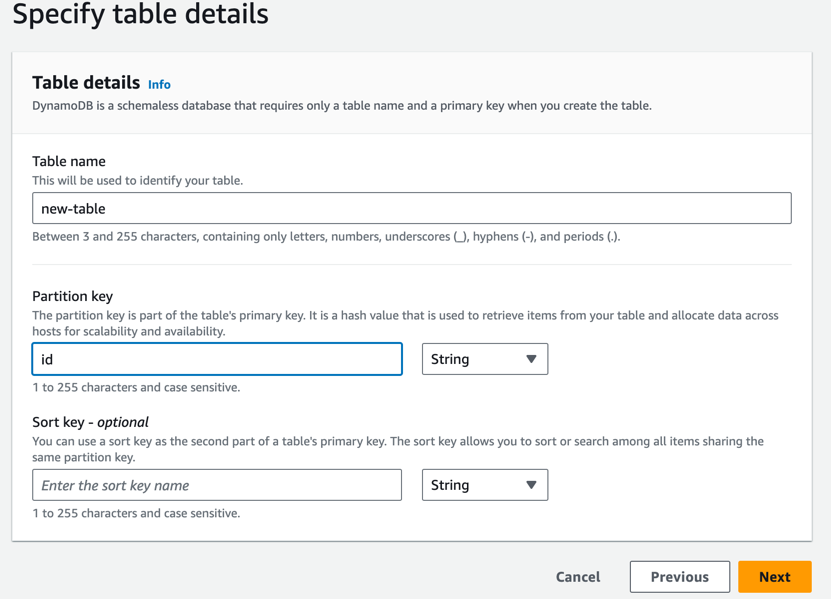
Once export is completed we will see a new DynamoDB table created with full dump extracted from export.
The Challenges when Running native AWS DynamoDB import/export
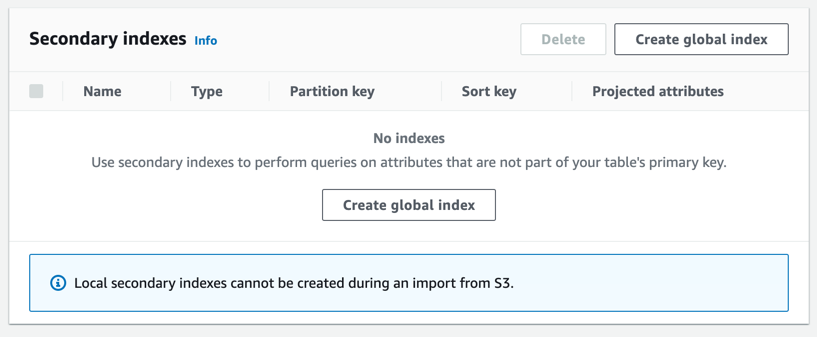
- indexes are mentioned as supported entities in the documentation, however LSIs (Local Secondary Index) actually are not supported - we can create only Global Secondary Index when preparing Import.
- the target table is created by Import Job (you do not have control to it) and since LSIs can be created only at table-creation time - we can not create LSIs manually.
- data ingestion into empty or existing table is not supported. Export always creates a new table.
So if we are actively using LSIs in source table (and we are using them a lot) DynamoDB import is not operable - it will create distinct table without LSIs that will not support our data access patterns.
Analyzing DynamoDB Export files in AWS S3
Let’s check how DynamoDB export files are organized and create our own tool that will allow process them and ingest into any table we want.
1
2
3
4
[cloudshell-user~]$ aws s3 ls ddb-export/AWSDynamoDB/
PRE 01689247414762-5086b7df/
PRE 01689404115192-c6c0f644/
PRE 01689743940694-b639f775/
These are different exportIDs, when running Export job it creates unique virtual folder where all content is located. export id starts with the Epoch Unix TimeStamp
1
2
3
4
5
6
7
[cloudshell-user~]$ aws s3 ls ddb-export/AWSDynamoDB/01689743940694-b639f775/
PRE data/
2023-07-19 05:32:43 0 _started
2023-07-19 05:32:42 792 manifest-files.json
2023-07-19 05:32:41 24 manifest-files.md5
2023-07-19 05:32:42 657 manifest-summary.json
2023-07-19 05:32:41 24 manifest-summary.md5
Inside latest export:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
{
"version": "2020-06-30",
"exportArn": "arn:aws:dynamodb:eu-west-1:123456789012:table/demo-table/export/01689743940694-b639f775",
"startTime": "2023-07-19T05:19:00.694Z",
"endTime": "2023-07-19T05:24:05.750Z",
"tableArn": "arn:aws:dynamodb:eu-west-1:123456789012:table/demo-table",
"tableId": "00000000-0000-0000-0000-000000000000",
"exportTime": "2023-07-19T05:19:00.694Z",
"s3Bucket": "ddb-exports",
"s3Prefix": null,
"s3SseAlgorithm": "AES256",
"s3SseKmsKeyId": null,
"manifestFilesS3Key": "AWSDynamoDB/01689743940694-b639f775/manifest-files.json",
"billedSizeBytes": 31293270,
"itemCount": 21253,
"outputFormat": "DYNAMODB_JSON"
}
manifest-summary.json contains all metadata about export details, we can use it in tool for data integrity verification and stat. Also, it has link to manifestFilesS3Key
1
2
3
4
{"itemCount":7255,"md5Checksum":"1/dzq1ZMskGUHTCNhVg1rg==","etag":"0000-1","dataFileS3Key":"AWSDynamoDB/01689743940694-b639f775/data/kviqvz6xlq47hchzfxaab7jir4.json.gz"}
{"itemCount":1434,"md5Checksum":"iW+W2Gi5q7nDKJYSfSTX0Q==","etag":"0000-1","dataFileS3Key":"AWSDynamoDB/01689743940694-b639f775/data/hfgoihwfpaytldayfiuvgwqd2u.json.gz"}
{"itemCount":12088,"md5Checksum":"4WwA4cvy5gg0HbxE29ehIw==","etag":"0000-1","dataFileS3Key":"AWSDynamoDB/01689743940694-b639f775/data/ngtyva35se3q7azm7imain3tte.json.gz"}
{"itemCount":476,"md5Checksum":"YDCCKHlzPoHed6qIE+hgqw==","etag":"0000-1","dataFileS3Key":"AWSDynamoDB/01689743940694-b639f775/data/nokdhrsyqu7bhjfqutddd4qk6e.json.gz"}
manifest-files.json contain set of data dumps for the table with virtual paths.
The actual dump of export is located in the following virtual path - in current scenario it is stored in dynamoDB JSON json.gz format (also dynamo support CSV and Amazon Ion):
1
2
3
4
5
[cloudshell-user~]$ aws s3 ls ddb-export/AWSDynamoDB/01689743940694-b639f775/data/
2023-07-19 05:32:43 142092 hfgoihwfpaytldayfiuvgwqd2u.json.gz
2023-07-19 05:32:46 1038746 kviqvz6xlq47hchzfxaab7jir4.json.gz
2023-07-19 05:32:44 1786697 ngtyva35se3q7azm7imain3tte.json.gz
2023-07-19 05:32:45 66424 nokdhrsyqu7bhjfqutddd4qk6e.json.gz
Proposed Solution: Introducing an Import Tool
Now, knowing the structure of dump files, we can create a tool that will read them and ingest into any table (with LSI or without). Tool, receives path to S3 export folder, exportID and target Table name as input parameters. Then it reads unpackages json.gz files, reads them and performs put operations into new table.
To run more effectively import tool supports parallel processing for each chunk of json.gz. To make sure that we do not stress the storage and have enough WCU before execution, import tool will increase WCU and once finish return back.
flowchart TD
A[Read Arguments] -->|S3, exportID, target_table| B[Read meta from manifest-summary.json]
B -->|path to each /data/*.json.gz| C[Read info about each data chunk from manifest-files.json]
C -->|based on Items count and parallel threads | D[Increase WCU for Table]
D -->|Process /data/*json.gz files in parallel| E[ingest into target Table]
E -->|migration completed | F[Decrease WCU for Table]
F --> G[show stat]
You can check import tool source here: https://github.com/tsypuk/aws_dynamo_import
Import tool key features:
- support writes into existing DynamoDB Table
- allows to configure target table with desired setup - precreate LSIs, post create GSI
- show details about export data
- outputs progress and statistics with timing and iterations per second
- supports parallel processing by dividing data into chunks (each chunk is ingested in parallel)
- increases WCU before data migration, decreases after
- has control of pool size for parallel execution
DataSet for Export verification Experiment:
- DynamoDB Tabel contains 4 indexes:
- 1 LSI (full projection)
- 3 GSI (full projection)
- Data Volume: 31.7 megabytes
- Items count: 21253
- avg Item size: 1,240 bytes
Estimated WCU Calculation:
1 Write Capacity Unit (WCU) = 1 write of Data up to 1 KB/s. For writes greater than 1 KB, total number of writes required = (total item size / 1 KB) rounded up 2 WCU 1,2K = rounded up 2WCU
Throughput for single write thread is ~16 Items/sec
Estimated Table WCU: 16*2 = 32WCU
Experiment 1: (Running in a single thread no parallelism)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
/usr/local/bin/python3.10 aws_dynamo_import/main.py --export=01689743940694-b639f775 --bucket=dev.ddb-export --table=test-import --pool=1
S3 bucket with export: ddb-exports
S3 SSE algorithm: AES256
export output format: DYNAMODB_JSON
Export ARN: arn:aws:dynamodb:eu-west-1:123456789012:table/table-source/export/01689743940694-b639f775
Export duration: 2023-07-19T05:19:00.694Z - 2023-07-19T05:24:05.750Z
Export execution time: 2023-07-19T05:19:00.694Z
Source Exported Table: arn:aws:dynamodb:eu-west-1:123456789012:table/table-source
Items count: 21253
Items count calculated in export chunks: 21253
Chunk size is per process: 21253
Processing 7255 items from AWSDynamoDB/01689743940694-b639f775/data/kviqvz6xlq47hchzfxaab7jir4.json.gz
Processing 1434 items from AWSDynamoDB/01689743940694-b639f775/data/hfgoihwfpaytldayfiuvgwqd2u.json.gz
Processing 12088 items from AWSDynamoDB/01689743940694-b639f775/data/ngtyva35se3q7azm7imain3tte.json.gz
Processing 476 items from AWSDynamoDB/01689743940694-b639f775/data/nokdhrsyqu7bhjfqutddd4qk6e.json.gz
100%|██████████| 21253/21253 [20:50<00:00, 17.00it/s]
Wait 5 seconds to free WCU
| WCU consumption in the peak | Import duration | aggregated ingestion rate |
|---|---|---|
| 32.3 WCU | 20 min:50 sec | 17.00 it/s |
In the peak Import consumed 32.3 WCU which is very accurate to our 32 WCU estimate
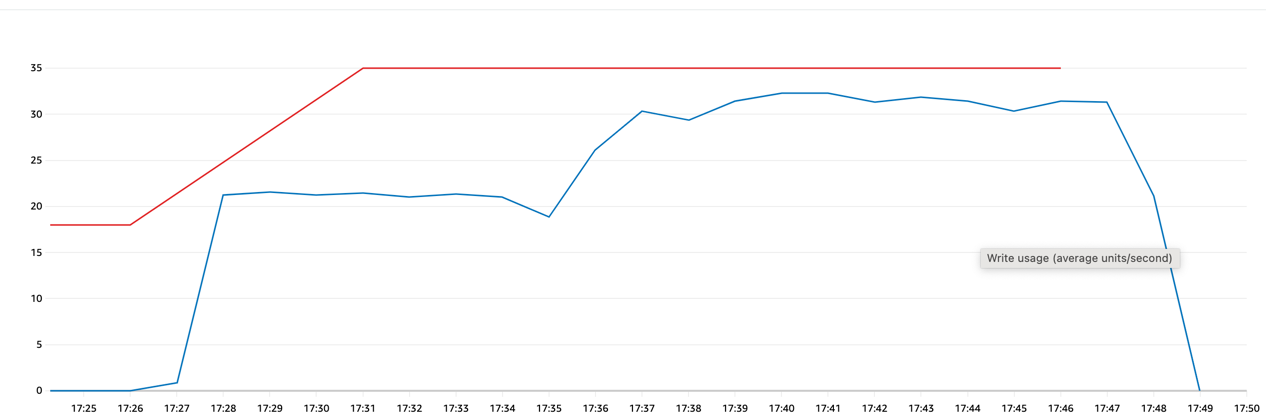
An interesting observation is the WCU consumption pattern during data import. It starts at 21.6 WCU, decreases to 18.86, and then reaches a maximum of 32.2 WCU.
This pattern consistently repeats when running the data import again. The variation in item size and their distribution within export chunks appears to be the contributing factor. As the chunks are processed in the same sequence, write pattern repeats consistently.
The recurring pattern is likely due to the unique characteristics of the data being imported. Each item’s size impacts the WCU consumption, and their distribution within chunks affects the overall pattern.
Understanding this behavior is crucial for optimizing the data import process and ensuring efficient resource utilization. By leveraging this insight, one can enhance the import strategy and achieve better performance during data transfer.
Experiment 2: (Running 20 parallel threads)
Now let’s see how we can speed up the process by spreading ingested data into equal chunks and ingesting each chunk in parallel with 10 threads.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
/usr/local/bin/python3.10 aws_dynamo_import/main.py --export=01689743940694-b639f775 --bucket=dev.ddb-export --table=test-import --pool=10
S3 bucket with export: pl-int-ddb-exports
S3 SSE algorithm: AES256
export output format: DYNAMODB_JSON
Export ARN: arn:aws:dynamodb:eu-west-1:123456789012:table/source-table/export/01689743940694-b639f775
Export duration: 2023-07-19T05:19:00.694Z - 2023-07-19T05:24:05.750Z
Export execution time: 2023-07-19T05:19:00.694Z
Source Exported Table: arn:aws:dynamodb:eu-west-1:123456789012:table/source-tabel
Items count: 21253
Items count calculated in export chunks: 21253
Chunk size is per process: 2125
Processing 7255 items from AWSDynamoDB/01689743940694-b639f775/data/kviqvz6xlq47hchzfxaab7jir4.json.gz
Processing 1434 items from AWSDynamoDB/01689743940694-b639f775/data/hfgoihwfpaytldayfiuvgwqd2u.json.gz
Processing 12088 items from AWSDynamoDB/01689743940694-b639f775/data/ngtyva35se3q7azm7imain3tte.json.gz
Processing 476 items from AWSDynamoDB/01689743940694-b639f775/data/nokdhrsyqu7bhjfqutddd4qk6e.json.gz
100%|██████████| 2125/2125 [01:59<00:00, 17.71it/s]
100%|██████████| 2125/2125 [01:59<00:00, 17.85it/s]
100%|██████████| 2125/2125 [02:00<00:00, 17.69it/s]
100%|██████████| 2125/2125 [02:00<00:00, 17.66it/s]
100%|██████████| 2125/2125 [02:02<00:00, 17.35it/s]
100%|██████████| 2125/2125 [02:04<00:00, 17.04it/s]
100%|██████████| 2125/2125 [02:05<00:00, 16.95it/s]
100%|██████████| 2125/2125 [02:07<00:00, 16.63it/s]
100%|██████████| 2125/2125 [02:08<00:00, 16.48it/s]
Wait 5 seconds to free WCU
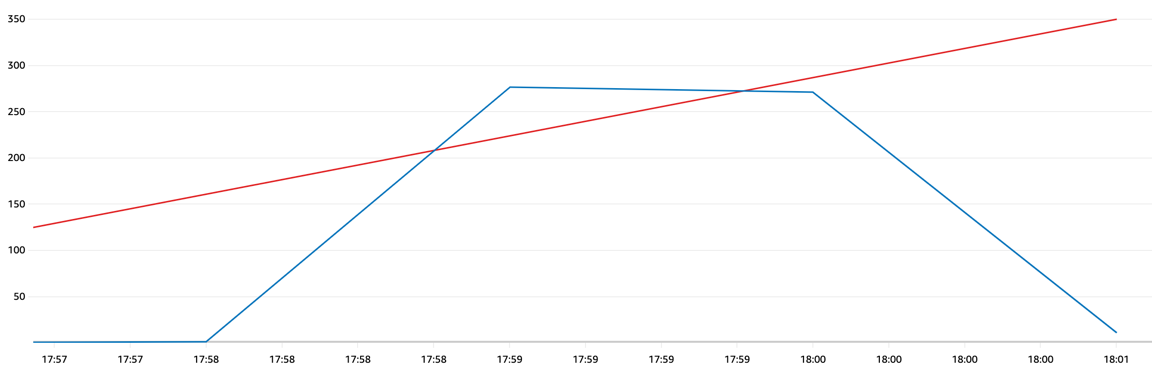
| WCU consumption in the peak | Import duration | aggregated ingestion rate |
|---|---|---|
| 276 WCU | 02 min:08 sec | 170.00 it/s |
We achieved a linear performance increase by increasing the concurrent pool from 1 to 10 threads. This scaling resulted in a substantial boost in ingestion throughput, significantly reducing the import time.
Conclusion
Transferring DynamoDB tables with AWS DynamoDB Import/Export from S3 offers significant advantages, but it also comes with challenges. By developing a custom import tool, we can overcome these obstacles and ensure a seamless and cost-effective data migration process. The proposed robust tool’s with performance optimization, error handling, parallel data processing scaling, ingestions items count verification and cost control measures will result in a successful and efficient DynamoDB table transfer experience.